

When we create new things, we differentiate. To claim that differentiation, we iron a brand to it: a unique identifier that represents itself. To grow those new things we’ve created, we market its brand. We’ve been doing this for about 5000 years, from the ancient Egyptian artisans to the modern Metaverse content creators. Branding activities have always been and will always be a centerpiece of innovation and culture.
Currently, a brand could be a piece of text, an image, or a multimedia clip, which claims its uniqueness among others in the same domain and conveys its own ideas. Brand identity could appear in many forms online: product descriptions, social media posts, you name it, and the internet hosts a wealth of these brand images. When consumers view a brand’s image, they associate it with their preconceptions about the brand and how it compares to other brands. Successful branding creates positive relationships with consumers who carry a perception of the brand’s quality and trustworthiness. Creators want to know whether people feel good about their brand, whether there are copycats of their brand, whether they need to grow into new sectors, and so much more. However, the tools available today for brand creators to address those key questions are insufficient and short-term–like duct tape on a leaking pipe.
This is why we focus on developing a search engine for branding activities.
Challenges
Immediately, we’re facing a number of big technical challenges (existing tools are like duct tapes for a reason).
Data Challenges. We need a scalable data infrastructure to gather branding information. Our goal is bold and simple: our dataset should be large and specific enough to answer the following questions.
- How many brands are there in the whole world? How do they differentiate their brand image from others and convey their unique message? Which companies own them and what do they do? How each brand is perceived by its customers?
- What are all the products being sold on earth right now? What are their brands and how do they protect the brands?
- What is the knowledge graph that involves brand owners, sellers, products, infringement cases, attorneys and law firms look like, and how do we derive insights from this graph?
Unlike other vertical search engines, e.g, Google Scholar or Yahoo Finance, a brand search engine is much more challenging even at the data level. We must reach the far corners of the web to gather image, text, and multimedia data that are suitable. In addition to domain-specific data sources, we need to harvest information from the vast expanse of the web and establish our own standardized, dynamic, and heterogeneous dataset. This process is like getting the berries out clean from a chantilly cake. Precision and scalability are key.

Algorithmic Challenges. Brand recognition turns out to involve many fundamental challenges to the field of AI. I will elaborate on image and text respectively.
Brand Recognition in Images
Goal: Recognize any brand appearances in any given image

Challenges
- Class Explosion. Usually, object detection or recognition models deal with class numbers ranging from 1 ~ 1000. For example, in autonomous driving, the models are taught to recognize 20~30 traffic objects. In the great benchmark of MS COCO, there are 80 classes and 1K classes in the ImageNet. In our case, there are more than 1 million brands that appear in pictorial forms in the US alone. Moreover, it’s even difficult to collect enough training instances of them, let alone labeling a significant part of them. The table below summarizes the class explosion challenge.
- Object Variety in Branding Images. First, there could be image/text hybrid, or even language hybrids. Second, the objects could be really abstract. Third, there could be distortion, angling, different lighting conditions, complex backgrounds, and so on. The model needs to be reliable against all of these conditions.
- Appearance Variety per Brand. As it shows below, one brand concept could appear in a variety of forms. The concept is the same, however, the appearances could vary dramatically. The model must learn the fundamental themes of a brand’s concepts instead of colors or textures — as the majority of the pretrained benchmark models do.
Goal: Detect any mentions about a brand, its products, and the product features in any given text.



Challenges
- Context Matters. The majority of English words are actually registered brand marks. However, when we use the words, we don’t always refer to their branding meanings. Therefore, simple word matching would never work. Here is an example. (brand, product, and product feature being labeled with red, green, and blue respectively.)
- Grammar Sometimes Does Not Matter. Especially in the eCommerce domain, a product title could be literally written as “chicago dogs zephyr patron hot dog grey adjustable strapback cap”, which breaks the majority of NLP models trained with normal grammar sentences.
3.Abbreviations are everywhere. For example, one could write “my new NB shoes are very comfortable. It says it only weighs 10 oz. Crazy!” Our model must learn the different names, including slang, of a brand in order to gather all instances of a brand’s usage.
Infrastructure Challenges. A comprehensive knowledge graph that provides insight into all brands, their products, and related companies is still in the works. Currently, Huski supports the largest knowledge graph in the field. However, there are millions of brand images that appear in image or text forms. There are also billions of products. All those entities form a graph with edges representing all kinds of relations that are consistently changing and growing. Being able to build and maintain such a dynamic knowledge graph and support low latency queries (e.g. 200ms) is another challenge to our data infrastructure.
Last but not least, we are a startup. It goes without saying that we need to be smart about solving all the above challenges while staying on budget. To say the least, it’s difficult.

Breakthroughs
Despite the challenges, we wouldn’t be writing this article if we haven’t advanced in all of those directions. In particular, we are proud to share a couple of breakthroughs that made the first branding search engine possible.
We’ve found a way, without labeling any data, to reliably detect over 1,000,000 pictorial brands in real-life images. Learning by unsupervised show-and-tell, our model represents what’s possible at the frontier of computer vision. It learns to detect brands even in very challenging scenarios.


The model can also go further to recognize highly blurred, distorted, and textured brand materials. See how our model still recognizes the Monster logo when Google Image Search gives some irrelevant grey images.
We’ve found a way, without labeling any data, to reliably detect over 3,000,000 textual brands in texts. Our model recognizes the brand name, the product, and the product features in common English or product titles or descriptions. The model uses a new paradigm — named entity recognition with entailment learning — to classify brands. It also recognizes the context so that it wouldn’t blindly treat every word as “brand” simply because they appeared in a “brand mark database”. A few examples are as follows. (Color code: brand /product /product features)
Multitask search. We are also the first to introduce “multitask search” in a brand search engine. People can use the combination of image and text in one single query and get a unified search result. The picture below shows how we use it in a trademark registrability analysis. More applications of multitask search to come later.

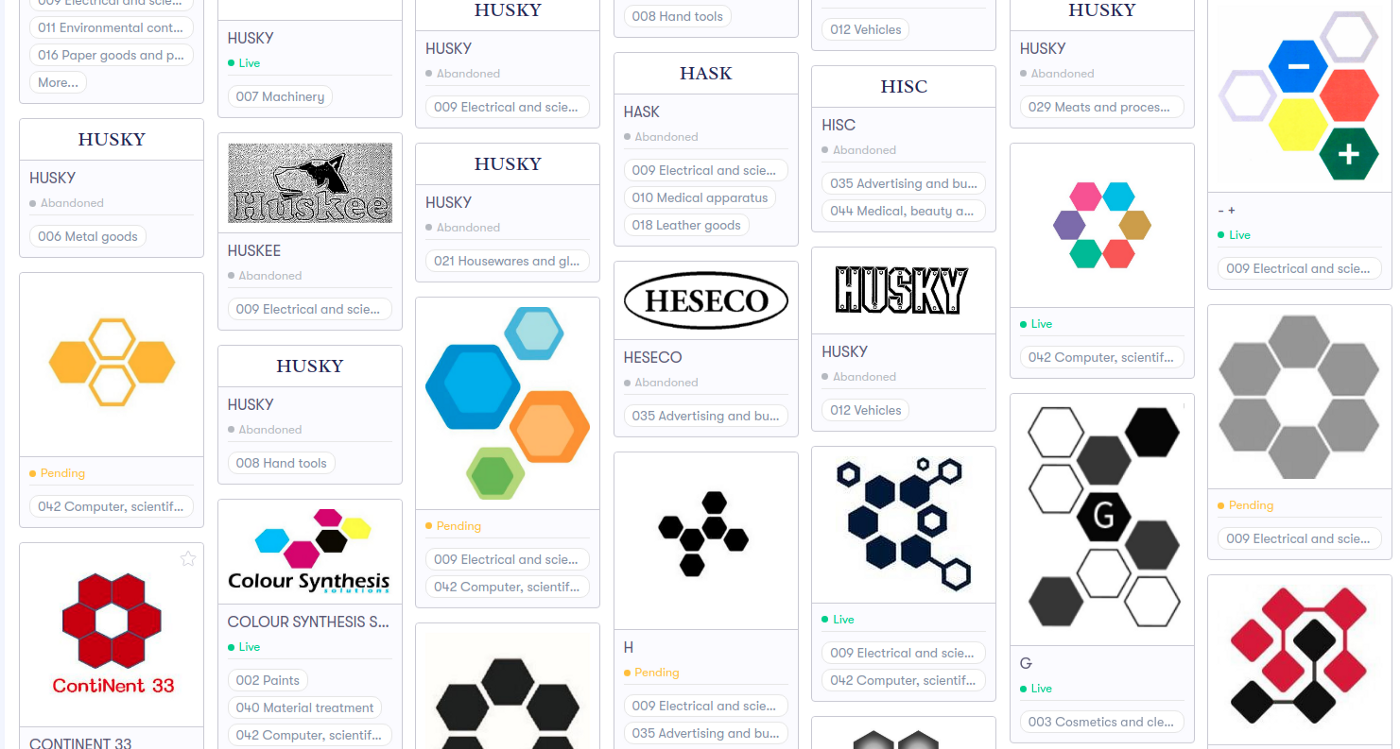
We found a way to efficiently harvest branding data across all Internet, including central marketplaces such as Amazon, eBay, or independent places like Shopify sites. We also keep monitoring all brand/trademark registrations, lawsuits, and other dynamics within the US. Our knowledge graph is derived, by the AI breakthroughs, from such data and we are proud of serving the queries very efficiently.
Conclusion
Although we’re still in the early days of our search engine, we are very excited to see the future possibilities which could help creators discover their brand’s footprint, understand the contexts, and take actions to protect and grow their brands. The challenges are unique and exciting. The technologies are capable of enabling many things. And we are just getting started.
Visit www.huski.ai to find out more!